Classificação de objetos#
O que é classificação?#
Simplificando, a classificação fenotípica trata de categorizar objetos em diferentes grupos com base em seus aspectos (também conhecidos como medidas).
📏 Como faço para medir?
A classificação fenotípica pode ser realizada de algumas maneiras diferentes. Uma maneira de decompor isso é pela classificação não supervisionada versus supervisionada.
Na classificação supervisionada, um ser humano fornece informações sobre como os diferentes grupos de objetos devem ser, fornecendo exemplos representativos de cada grupo em um conjunto de dados de treinamento. O computador então aprende como atribuir objetos a grupos com base nas medidas, testando modelos em relação ao conjunto de dados de treinamento fornecidos pelo usuário.
Por exemplo, você pode classificar células com base em um fenótipo visual e treinar um classificador de aprendizado de máquina para derivar quais intervalos de medição estão associados a diferentes classes. Essa é uma classificação supervisionada porque uma pessoa está fornecendo instruções sobre quantas classes devem haver e exemplos de como cada classe deve ser para o computador aprender. Um exemplo disso pode ser anotar um subconjunto de células que estão em diferentes estágios de mitose e treinar um classificador para usar suas características para encontrar outras células nesses estágios.
Na classificação não supervisionada, você agrupa objetos com base em suas medidas, mas sem nenhuma orientação definida por humanos sobre quantos grupos existem ou como devem ser os grupos.
Por exemplo, você pode medir centenas ou milhares de características de células de muitos tratamentos, como é típico em experimentos de perfis de células em grande escala. Em seguida, você pode deixar o computador agrupar as células em vários grupos diferentes com base em medidas semelhantes. Esta é uma forma de agrupamento não supervisionado, onde você observa quais grupos emergem de um computador considerando apenas suas medidas, e não as classes que impomos como pesquisadores. Esse tipo de experimento de agrupamento não supervisionado pode fornecer novos resultados, mas também podem ser mais difíceis de interpretar; consulte este protocolo24 para mais informações.
⚠️ Onde as coisas podem dar errado?
Medições válidas ainda são importantes A classificação pode ser simples ou complexa, mas os resultados sempre dependem da validade/qualidade das medidas. Por esse motivo, todas as ressalvas das seções de medição anteriores também se aplicam aqui.
As máquinas são preguiçosas Os classificadores de aprendizado de máquina não vão necessariamente aprender os recursos biologicamente relevantes que distinguem objetos de grupos distintos. Características confusas ou características que variam dependendo do fenótipo, mas não estão biologicamente relacionados a ele, podem limitar a utilidade do classificador e levar a conclusões incorretas. Por exemplo, se os médicos costumam colocar réguas ao lado de tumores de aparência maligna e não ao lado de tumores benignos e tentam treinar um classificador de aprendizado de máquina para distinguir maligno de benigno, o modelo pode aprender a classificar imagens com réguas como malignas sem levar em consideração nenhuma das características relevantes dos tumores. Este é um exemplo real 25. Se possível, examinar de quais recursos seu modelo depende para classificar objetos pode ser uma maneira de verificar isso. Também é importante padronizar como você captura imagens de suas diferentes classes de objetos e incluir um conjunto de treinamento grande o suficiente com imagens com muita variação. Você não gostaria que todas as suas células positivas viessem de amostras que você imaginou em março e todas as suas células negativas de amostras que você imaginou em janeiro, por exemplo.
Violando as suposições do modelo Se estiver usando um classificador de aprendizado de máquina, diferentes modelos vêm com diferentes suposições incorporadas. Se você está começando, pode ser difícil saber qual escolher. Existem ferramentas interativas como CellProfiler Analyst 26 e [Piximi](https://www. piximi.app/) que facilitam o treinamento de um classificador, especialmente se você não sabe linguagem de programação.
Limites confusos A maioria dos métodos de classificação supervisionada, em que o usuário atribui objetos a uma pontuação ou a uma classe, trata cada classe como uma entidade totalmente separada; a biologia raramente é tão organizada. Por exemplo, um classificador supervisionado para a fase do ciclo celular deve atribuir uma célula a uma fase, mas, na verdade, a progressão através do ciclo celular não é um processo perfeitamente semelhante a um interruptor, como pode ser visualizado por medições de células individuais (coloridas por sua classe dada por um observador humano). Métodos mais sofisticados podem ser necessários para classificar fenótipos mais dinâmicos
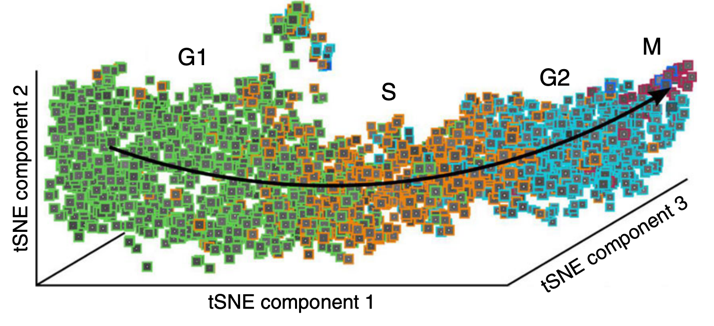
Fig. 7 A divisão estrita em classes supervisionadas pode ser complicada para processos biológicos dinâmicos. Adaptado de Eulenberg, P., Köhler, N., Blasi, T. et al. Reconstruindo o ciclo celular e a progressão da doença usando aprendizado profundo. Nat Commun 8, 463 (2017) 27#
📚🤷♀️ Onde posso aprender mais?
📄 Estratégias de análise de dados para perfis de células baseados em imagens 28
📄 Score de diversas morfologias celulares em telas baseadas em imagens com feedback iterativo e aprendizado de máquina 29
🎥 iBiology série de vídeos: Medição e classificação de fenótipos
📄 Interpretando Perfis Baseados em Imagens Usando Matriz de Similaridade e Visualização de Células Isoladas 24